How an AI Agent Reached the Top 3 by Learning to Adapt
A single developer with one GPU reached 3rd place on a world-class GPU optimization leaderboard — not by writing faster code, but by building a system that learns what’s fast on any hardware it runs on, and by using an AI agent to drive the hundreds of experiments no human could sustain.
A natural question: how can one person with one GPU compete against well-funded teams running massive cluster sweeps? The answer is depth over breadth — understanding why something is fast, not just that it’s fast — and trusting an AI agent to sustain the grueling hypothesis-test loops that get you there.
Results at a Glance
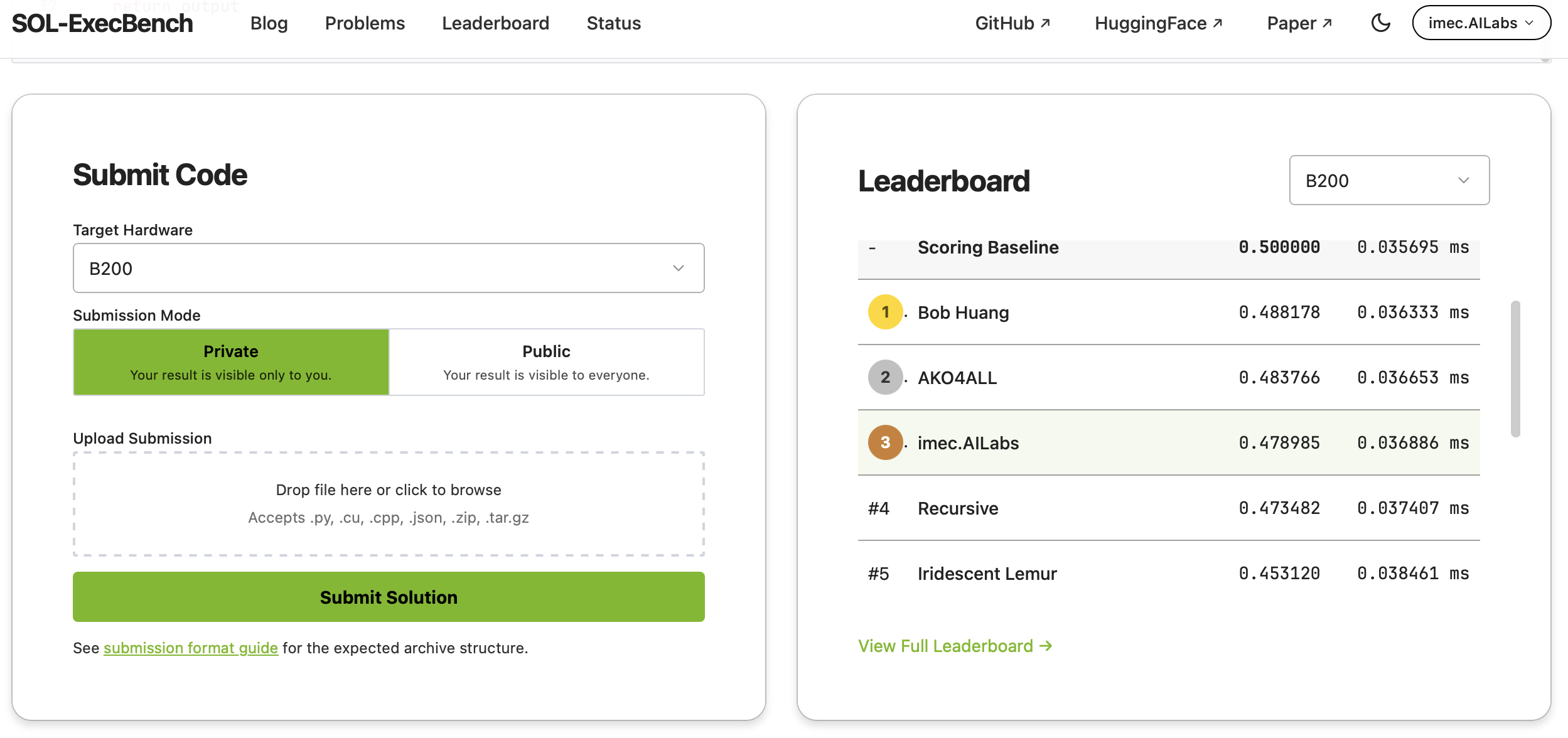
- 3rd place on the SOL-ExecBench global leaderboard (as of June 29, 2025; currently 4th after a later competitor entry)
- SOL score: 0.478985 | Latency: 0.036886 ms per operation
- Within ~2% of the top score on a problem where the ceiling is razor-thin
- One GPU, no massive compute cluster, same vendor library as every other competitor
The Challenge
The task was to speed up a core AI operation — a large matrix multiplication followed by a small addition (the “residual”) — on NVIDIA’s newest Blackwell B200 GPU. The benchmark scores against a speed-of-light lower bound: the closer the latency to that bound, the higher the score.
Two twists made it genuinely hard:
- 16 different input sizes. The score is the mean across all of them. Winning on one size while losing on others gets you nowhere.
- The judge’s machine is different from yours. What runs fastest on your local setup may run slowest on the evaluation server, because even minor software version differences change which internal routines the GPU library selects.
The Journey: Four Phases
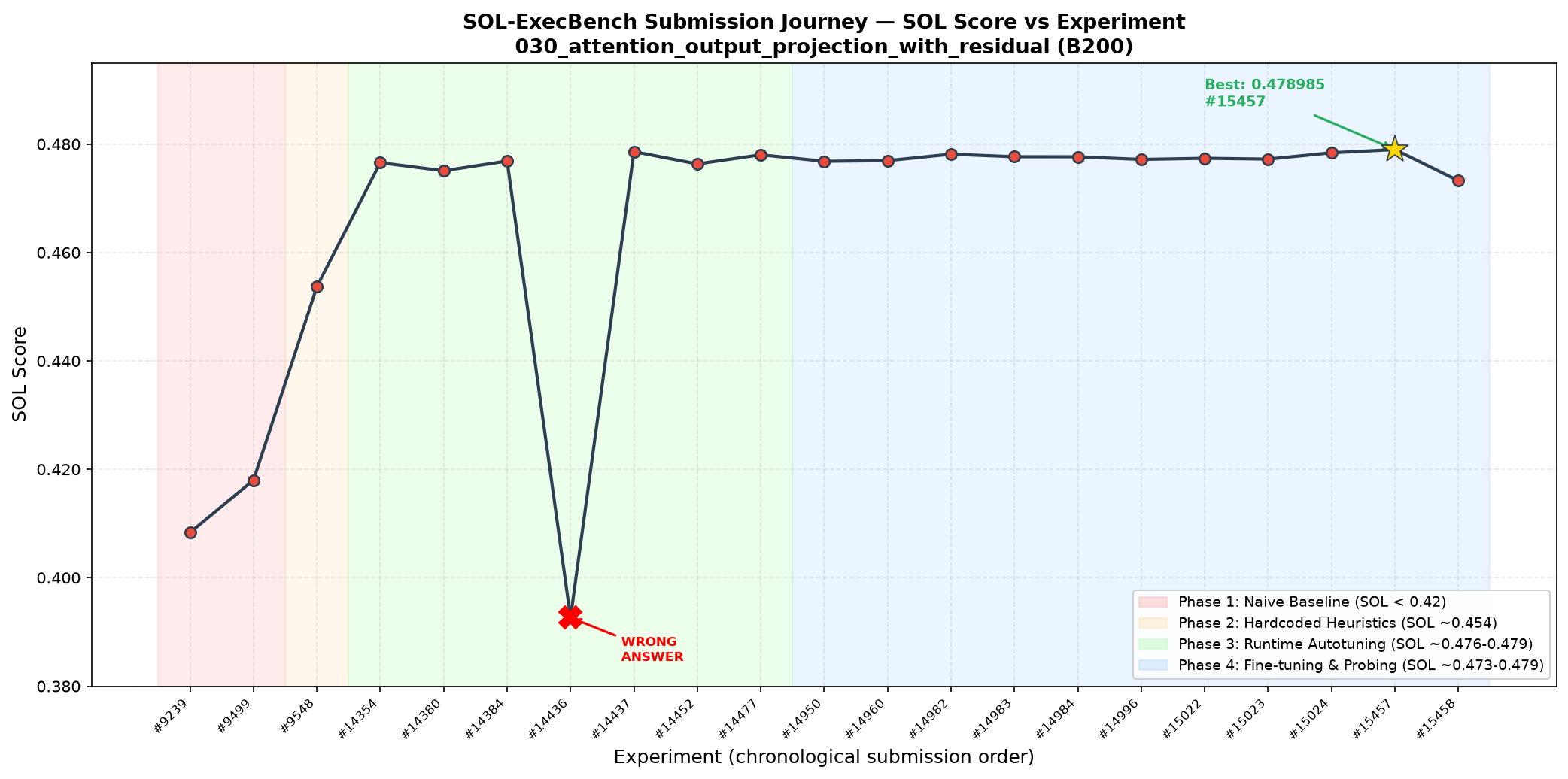
Phase 1 — Trust the Defaults (~84% of top score)
The starting point used NVIDIA’s standard library (cuBLASLt) with default settings, plus a hand-written CUDA kernel to add the residual afterward. The result was surprisingly slow — vendor defaults simply aren’t tuned for every unique workload shape. It became immediately clear that the “default path” was leaving enormous performance on the table.
Phase 2 — Memorize What Works (~94% of top score)
The agent profiled all 16 shapes and discovered that each preferred a different algorithm variant. These per-shape winners were hardcoded into the system — one shape at a time, validating the full 16-workload set after each change. Local speeds skyrocketed.
A second key idea landed here: fuse the residual addition into the matrix multiply itself. Instead of running the multiply and then a separate add kernel, the library’s built-in path computes both in a single call — the addition happens “for free” inside the multiply’s epilogue. The separate kernel disappeared entirely.
The trap: When submitted to the leaderboard, scores were stuck. The leaderboard ran a slightly different library version, meaning hardcoded “Algorithm #2” pointed to a completely different, slower calculation method on their machine. 15 of 16 shapes were running below baseline. Hardcoded indices are not portable — they’re just memorized labels that mean different things on different systems.
Phase 3 — Learn On the Spot (~100% of top score, 3rd place)
The solution couldn’t be static; it had to be dynamic. The architecture was rewritten to perform runtime autotuning.
Now, when the code initializes (during the un-timed warmup phase), it runs a lightning-fast mini-tournament on whatever hardware it finds itself on. It tests a curated list of algorithmic strategies, measures them using the exact timing methodology of the leaderboard, and locks in the winners. The steady-state path is a single library call with the cached algorithm — zero inference overhead.
Four interlocking ideas made the autotuner trustworthy:
-
Cold-cache timing. The evaluation server flushes the GPU’s L2 cache between iterations. So the autotuner does too — a large memory clear before every candidate timing. Hot-cache tuning picked different, wrong winners, because the judge shifts data pointers between iterations, defeating any warm-cache assumption. Cold-cache is the only honest proxy for real evaluation conditions.
-
Dual fused/split strategy. Per-shape choice: fold the residual into the multiply (fused) vs. keep them separate (split). Large input sizes prefer fused — less overhead. Small input sizes (256/512/586) often prefer split — less epilogue pressure. The autotuner tries both and picks per shape.
-
Exploring hidden configurations. The library has algorithm variants it doesn’t surface through its default API. The tuner manually injects parallelism settings (split-K factors), validates them, and tests them. This surfaces configurations the standard search never returns — configurations that may differ between library versions, which is exactly the portability gap that broke Phase 2.
-
Accuracy as a stability filter. A strict quality check (absolute tolerance of 0.008) was applied to every candidate. This isn’t just about correctness — it’s a variance filter. Algorithms that barely pass a loose tolerance tend to use non-deterministic reduction paths; they look fast in tuning but regress in production. This was tested directly: loosening the tolerance accepted faster-looking configurations that regressed on the leaderboard. Strict accuracy won.
The agent’s insight that tied this together: it reverse-engineered the scoring formula, identified which shapes set the median score, diagnosed why the prior best was losing, and designed the minimal fix — stop hardcoding indices, let the code discover the best algorithm on whatever hardware it lands on.
The result jumped to 3rd place on the leaderboard, using the same cuBLASLt engine as everyone else.
Phase 4 — Prove There’s Nothing Left
To be absolutely sure the ceiling was reached, the agent ran a ladder of increasingly low-level approaches, each a separate track with its own stop condition:
| Level | Approach | Result |
|---|---|---|
| Library policy tuning | Heuristic-rank search + workspace variants | ✅ The winning level |
| Library exhaustive search | 5000 algorithm configurations (tile/stage/parallelism/swizzle) | Same winners as the 8-heuristic search |
| Template kernels | NVIDIA CUTLASS template library (74 configs) | 9–20% slower |
| Different engine | cuDNN backend matmul graph | 9–25% slower |
| Hand-written kernel | Full Blackwell-native assembly (TMA + tensor memory + cluster launch) | Mainloop matches the library; entire gap is the residual epilogue |
| Approximate math | FP8 / MXFP8 reduced precision | Fails correctness (59.5% matched vs 99% needed) |
The hand-written kernel track is the most instructive: a full custom kernel using every Blackwell-native feature got the compute mainloop to within +1.5% of the library. The entire remaining gap (~10%) was the residual addition in the epilogue — which the library fuses for free through its built-in path. The agent proved that fusing the residual in a custom kernel is architecturally correct but can’t beat the library’s optimized inline implementation. That negative result is itself a contribution: it locates the ceiling precisely.
A final architectural refinement: different shapes should be tuned with different timing statistics. Large shapes produce stable timings, so the median of 13 repetitions picks the right algorithm. Small shapes are noise-sensitive, so the minimum time picks better — it’s less biased by run-to-run variance. This is the most general architecture: autotuning + dual strategy + hidden config exploration + correctness gating + per-shape timing — exactly the portability-first design philosophy born from the Phase 2 failure.
Solution Architecture
The final codebase consists of roughly 450 lines of CUDA C++ with zero external dependencies beyond the standard cuBLASLt library. It operates in two clean steps:
-
Init (Warmup — Not Timed): Per shape: search across compute types, workspace sizes, heuristic algorithms, and parallelism factors → measure under cold-cache conditions → verify correctness → cache the winner.
-
Steady-state (Timed by Leaderboard): Execute a single library call using the cached optimal algorithm. Zero inference overhead.
What Made the AI Agent More Than a Script
The AI agent wasn’t just running a grid search. Four principles made its contribution genuinely original:
-
A living playbook. The agent maintained evolving operational rules — not a static plan. After each experiment, the rules updated: what to try next, when to stop a line of investigation, and what conditions a result must meet before being promoted. Each track had explicit stop conditions and a promotion gate (all 16 workloads pass; full-run improves ≥0.30%; dominant shapes don’t regress). This was the agent’s long-term memory and its discipline.
-
Working backwards from the score. Instead of “try things and see,” the agent reverse-engineered the scoring formula. It identified which input sizes most influenced the final score, diagnosed why the previous best was losing on those sizes, and designed the smallest possible fix to close that exact gap. It pointed out that the prior best was slower than the per-shape baseline on 15 of 16 shapes — the whole gap was a policy gap, not an algorithm gap.
-
Knowing when to stop. The agent treated every optimization track as a bounded experiment with an explicit exit condition. When a track’s best result couldn’t beat the current winner, the agent closed it and moved on — no sunk-cost fallacy. It forced the work to stop chasing new kernels and focus on choosing among the library’s existing ones.
-
Clean resets over patching. When an idea failed, the agent didn’t try to salvage it. It reverted to the last known-good state, documented why the idea failed, and ensured the same dead end was never revisited. When hot-cache tuning lost, it reset to cold-cache. When looser accuracy tolerances regressed, it reset to strict. This turned a potentially chaotic search into a disciplined, forward-moving process.
A Plain-Language Summary
Imagine a delivery driver with a GPS that offers several routes. The default route is often slow. One could memorize “take route #2 on Mondays” — but if the driver works in a different city, route #2 means something else entirely.
That was Phase 2: hand-memorized route numbers that broke on the judge’s “city” (a slightly different software version).
Phase 3 was the fix: let the driver test-drive every route at the start of each shift, time them under realistic conditions (traffic = cold cache), keep a notes file of which route won, and then just use that route all day. The test-driving happens once, off the clock; during actual deliveries there’s zero overhead.
The agent’s cleverness was in how it tested routes:
- It cleared the road before each trial so the test matched real traffic conditions.
- It tried two driving styles — “drop off the package on the way” (fused) vs. “drive first, drop off after” (split) — and picked per route.
- It invented new routes the GPS doesn’t normally show.
- It double-checked each trial’s result for accuracy, using a strict bar as a noise filter — routes that only barely passed were unreliable and rejected.
- It used different judging methods for different route types — averaging for long stable routes, taking the best trial for short noisy ones.
The result: a single GPU, one operator, beating teams with clusters — not by writing a faster multiply, but by being smarter about choosing among the library’s existing multiplies, and proving (via the custom-kernel track) that the library really was the ceiling.
The Big Picture
| What seemed like the problem | What was actually the problem |
|---|---|
| “We need a faster algorithm” | We need to pick the right algorithm from the library’s existing set |
| “We need to tune on our machine” | We need to tune on whatever machine the code actually runs on |
| “We need more compute for search” | We need smarter search — understanding the score, the cache, and the variance |
| “We need a custom kernel to win” | The library is the ceiling; the custom kernel proves it |
Why It Matters Beyond This Benchmark
The pattern here is broadly applicable:
-
Adaptive beats static. Any system that bakes in environment-specific choices is fragile. Systems that discover what’s best at runtime are portable and resilient.
-
Choosing well beats building new. The final solution uses only the vendor’s existing library — no custom math. The entire edge came from being smarter about selection: which variant, which strategy, which configuration, per workload.
-
AI agents enable depth. A human can form the strategy. But sustaining hundreds of structured experiments — each with setup, measurement, validation, and documentation — is where AI agents excel. The agent didn’t replace the human’s insight; it amplified the human’s capacity to act on that insight systematically.
-
Negative results locate the ceiling. Proving that a hand-written kernel can’t beat the library is as valuable as any speed improvement. It tells you exactly where to stop and why.
Takeaway
The biggest wins came not from writing faster code, but from understanding the system deeply — the scoring formula, the evaluation environment, the library’s hidden options, and the difference between “looks fast in testing” and “actually fast in production.” By trusting an AI agent to handle the grueling, highly structured hypothesis-testing loops, a massive server farm was not needed. One GPU, one developer, one AI agent — depth over breadth.